- Accueil
- > Les Annales
- > n° 4
- > Antiquité
- > La difficulté d’écrire une lettre en Mésopotamie: étude à partir d’une base de données relationnelle et du logiciel TXM
La difficulté d’écrire une lettre en Mésopotamie: étude à partir d’une base de données relationnelle et du logiciel TXM
Par Marine Béranger
Publication en ligne le 05 avril 2016
Résumé
Letter sending was invented at the end of the third millennium BC in Mesopotamia. The practice became much more widespread during the Old Babylonian Period (2002 BC-1595 BC), when letters were written for new communicative purposes by an increasingly literate population. Today, a corpus of nearly 7,000 letters written during this period, coming from around thirty archaeological sites, has been edited. These documents, written in the Akkadian language, were produced during four centuries in a wide variety of geographical and socio-linguistic contexts. The data and variables to consider are therefore numerous. In this article I will present two digital tools, a relational database and the textometry software TXM, with which I have been able to compare the quality and precision of the written messages as well as the linguistic and scriptural standards used by the senders, and, finally, which enable me to estimate the level of literacy of the scribes.
La communication par lettres fut inventée en Mésopotamie à la fin du IIIe mil. av. J.-C. Cette pratique prit de l’importance au cours de la période paléo-babylonienne (2002 av. J.-C. - 1595 av. J.-C.), lorsque survinrent de nouveaux besoins communicationnels et que davantage d’individus accédèrent à l’écrit. Environ 7000 lettres rédigées durant cette période, retrouvées sur une trentaine de sites archéologiques, sont aujourd’hui éditées. Cette documentation, écrite en langue akkadienne, fut produite pendant quatre siècles dans une très grande variété de contextes géographiques et sociolinguistiques. Les données et variables à considérer sont par conséquent nombreuses. Dans cet article, nous présenterons deux outils informatiques, une base de données relationnelle et le logiciel de textométrie TXM, que nous utilisons dans nos recherches afin de comparer la qualité et la précision du message écrit, les normes linguistiques et scripturales employées par les expéditeurs, et pour estimer le niveau de qualification des scribes.
Mots-Clés
Proche-Orient, Mésopotamie, Akkadien (langue), alphabétisation, Babylone, base de données relationnelle, communication écrite, écriture cunéiforme, Hammu-rabi, lettres (genre épistolaire), linguistique, Mari (Syrie), période paléo-babylonienne, pragmatique, psycho-linguistique, référence (linguistique), textométrie.
Table des matières
Texte intégral
Introduction
Cadre historique
1L’écriture fut inventée en Mésopotamie aux environs de 3300 av. J.-C., probablement par les Sumériens. Les premiers textes écrits permirent d’enregistrer des informations comptables (le nom de produits et de biens avec leur quantité, le nom ou la fonction des intervenants, la nature des opérations effectuées). Le genre épistolaire, contrairement à ce que relate le récit de son invention, n’apparut qu’au xxive s. av. J.-C., soit mille ans après l’invention de l’écriture1. Dans l’intervalle, une nouvelle population s’était établie en Mésopotamie et avait adapté l’écriture cunéiforme à la notation de sa propre langue (l’akkadien). Les premières lettres furent par conséquent rédigées, selon l’origine des locuteurs, en langue sumérienne ou akkadienne. Ce sont essentiellement des lettres d’affaire, liées à la gestion administrative comptable et au commerce individuel2. Ces lettres sont brèves et recourent souvent à un répertoire de phrases limité. Les lettres diplomatiques sont (presque) absentes de la documentation3.
2Après la chute du dernier empire sumérien, en 2002 av. J.-C., le pouvoir central éclata en multiples cités-États et de nouveaux besoins communicationnels survinrent. La lettre sortit du contexte bureaucratique et investit abondamment la diplomatie et l’administration générale. Elle fut de plus utilisée par des individus extérieurs au pouvoir royal et à l’administration. Dès lors, le nombre de lettres échangées augmenta considérablement, de même que la longueur du message écrit (certaines lettres ont une centaine de lignes).
3En raison du succès que connut la correspondance écrite à partir du iie mil. av. J.-C., les lettres de l’époque paléo-babylonienne (2002-1595 av. J.-C.) furent rédigées dans de nombreuses villes mésopotamiennes, dans des dispositifs communicationnels variés (privé, politique, administratif), et furent écrites par des individus appartenant à différentes communautés linguistiques (parlant le babylonien, l’amorrite, l’assyrien, le hourrite...) et aux statuts sociaux multiples (rois, administrateurs, marchands, religieuses, etc.).
4Parmi les assyriologues, l’idée est bien établie que la Mésopotamie est composée de différentes régions possédant chacune leur propre système graphique. Au contraire, ces chercheurs considèrent souvent que la forme écrite du dialecte paléo-babylonien, qui fut utilisé pour rédiger les lettres de la première moitié du iie mil. av. J.-C., était uniforme. Or, nous l’avons dit, ce dialecte fut utilisé dans une très grande variété de contextes géographiques et socio-linguistiques, sur une période de quatre siècles. L’ensemble de ces données rendait nécessaire et propice la comparaison de la production épistolaire rédigée dans la première moitié du iie mil. av. J.-C.
Catégories analysées et variables
5Dans notre recherche, nous avons voulu définir les traditions écrites présentes sur le territoire mésopotamien, et avons voulu comparer la qualité des lettres écrites. Pour ce faire, nous avons choisi d’analyser le lexique et les formules récurrentes, la précision de l’information énoncée (à travers l’analyse des chaînes de référence, des relations de discours et des subordonnées) ainsi que la précision de l’information transmise (par exemple, en comparant le recours aux citations ou au récit dans les différentes lettres). Nous comparons également les graphèmes et les formes graphiques, qui sont un fort indice régional. Parmi les variables externes, nous avons retenu le lieu et la date de rédaction, le dispositif communicationnel et l’origine sociolinguistique de l’expéditeur.
6Dans cet article, nous présenterons la base de données relationnelle Lea avec laquelle nous analysons la qualité et la précision du message écrit, et le logiciel TXM qui nous permet de comparer les normes linguistiques et scripturales des différentes lettres, et donne à réfléchir sur le niveau de qualification des scribes.
La base de données Lea
7Lorsque nous analysons une lettre, les catégories que nous observons sont nombreuses, c’est pourquoi il était nécessaire de trouver un outil informatique qui nous permettait d’enregistrer et de manipuler facilement les données extraites. Il fallait de plus un outil capable de mettre en rapport ces données avec les variables retenues (temporelle, spatiale et générique). À cette fin, une base de données relationnelle s’est révélée idéale.
Les chaînes de référence
Définition
8Afin de montrer l’utilité et le fonctionnement de la base de données Lea [acronyme de Lettres Antiques], nous présenterons la méthode que nous employons pour analyser les chaînes de référence.
9Une chaîne de référence désigne la « suite des expressions d’un texte entre lesquelles l’interprétation construit une relation d’identité référentielle »4. Cette définition inclut les anaphores, les cataphores, les exophores et les expressions co-référentielles. Lors d’une lecture des premières lettres paléo-babyloniennes, plusieurs exophores furent repérées. Il s’agissait de pronoms personnels et d’infixes de la 3e pers. utilisés sans que les individus auxquels ils renvoient soient mentionnés dans les lettres. Voici un exemple extrait de la lettre AS 22 6 (fig. 1)5 :

Fig. 1 : Lettre AS 22 6 © Marine Béranger (voir l’image au format original)
{kind=link}
Revers
˹a˺ -˹na˺ mi-ni-[i]m
[16] ˹ma-ag-ri-ta˺-ma
le-em-né-ti-a
[18] a-na be-˹lí˺-a
i-˹ta-wu-ú˺-[m]a
[20] l[i-b]i be-lí-[a]
k[i ú-š]a-am-ra-˹ṣú˺
10(15-19) Pourquoi disent-ils à mon seigneur, calomnieusement, des méchancetés contre moi et (20-21) comment peuvent-ils inquiéter mon seigneur ?
11Dans cet exemple, les exophores apparaissent aux lignes 19 et 21 sous la forme des infixes de la troisième personne du masculin pluriel. Les hommes dont il est question, qui calomnient l’expéditeur, ne sont jamais nommés. Ces infixes sont par conséquent impossibles à interpréter si l’on considère uniquement le contenu sémantique, verbal, de la lettre.
12L’interprétation des exophores de la lettre AS 22 6 pouvait reposer sur une présupposition (si l’expéditeur et le destinataire partageaient des connaissances sur le monde), sur les précisions que le porteur du message était chargé d’apporter à l’oral au destinataire, ou encore, ce qui est problématique, sur le contexte d’énonciation, auquel le destinataire n’avait plus accès au moment de la réception du message (si l’on suppose que ces exophores sont des déictiques qui n’ont pas été transposés, ou décontextualisés, à l’écrit). Leur interprétation, par conséquent, a dû être inférée par le destinataire à partir de ses connaissances et du contexte.
13Dans notre travail, nous n’évaluons pas la réception de la lettre, dans la mesure où les réactions du destinataire sont souvent inconnues (les commentaires des rois Samsi-Addu et Išme-Dagan, qui se plaignent des lettres difficiles à comprendre du roi Yasmah-Addu, font exception), mais analysons la qualité du texte écrit en évaluant la (im)possibilité que le message ait été compris ainsi que le coût cognitif du traitement de l’information. Les exophores, qui reposent sur des dispositifs pragmatiques, ont par exemple un coût de traitement supérieur à celui des formes dont l’interprétation repose sur la sémantique du texte6. Les raisons pour lesquelles les variations entre les lettres existent ne pourront qu’être envisagées. Ce pourrait être les conditions dans lesquelles la lettre était reçue (si la lecture de la lettre était accompagnée des commentaires oraux du porteur du message) ou encore la compétence des scribes, plus ou moins conscients des particularités du message écrit et des adaptations à effectuer.
Exemple d’utilisation
14La lettre AS 22 6 (supra) fut écrite au début du iie mil. av. J.-C., alors que ce moyen de communication était encore récent en Mésopotamie. Nous avons voulu comparer les données recueillies dans cette lettre et celles de son époque avec les données issues de lettres plus tardives.
15La figure 2 est une copie d’écran de Lea, notre base de données relationnelle7. Les informations enregistrées sont liées à une lettre unique (sur la capture d’écran, AbB 2 288). Les cinq onglets du haut correspondent à des niveaux d’analyse différents. L’onglet « Informations générales » (en haut à gauche) regroupe un ensemble d’informations générales et contextuelles relatives à la lettre, telles que sa référence-clef, son genre (lettre envoyée, brouillon, etc.), la date de sa rédaction, le statut des épistoliers, etc.
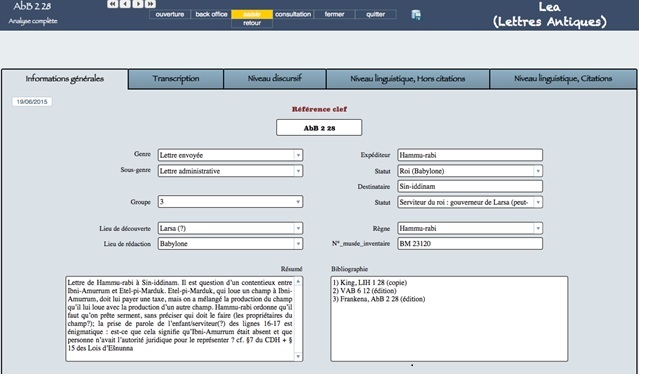
Fig. 2 : Informations générales © Marine Béranger (voir l’image au format original)
{kind=link}
16L’onglet « Niveau discursif » (fig. 3) réunit un ensemble d’analyses liées à la linguistique textuelle. Les données sur les chaînes de référence sont enregistrées dans cette rubrique. Les colonnes du tableau correspondent aux descripteurs retenus (structure et fonction syntaxiques de chaque expression référentielle, etc.).
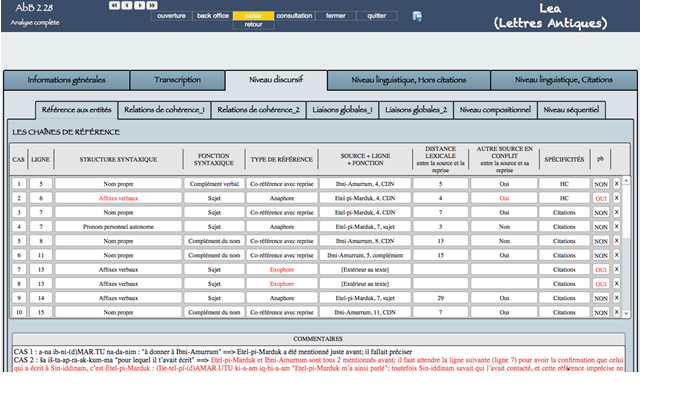
Fig. 3 : Les chaînes de référence dans AbB 2 28, lettre du xviiie s. av. J.-C © Marine Béranger (voir l’image au format original)
{kind=link}
17La mise en rapport des données contextuelles (les variables) avec les données issues de l’analyse des chaînes de référence s’effectue sous la forme de requêtes croisées. Il suffit de sélectionner un ensemble de critères à combiner en fonction des descripteurs et des variables que l’on veut associer. La figure 4 montre une requête portant sur les exophores du début du iie mil. av. J.-C. (groupe 1).
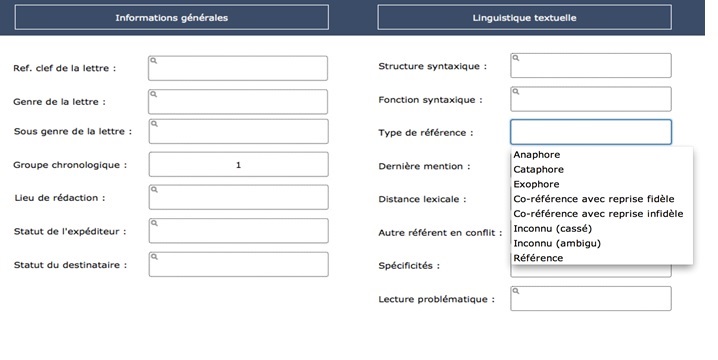
Fig. 4 : Exemple de requête croisée dans Lea © Marine Béranger (voir l’image au format original)
{kind=link}
18Le résultat de cette requête (fig. 5) montre que la base de données relationnelle a effectivement mis en relation les données portant sur les chaînes de référence avec la variable temporelle, puisqu’elle a trouvé tous les cas d’exophore dans les lettres du groupe 1. Elle a fait le tri entre toutes les informations pour n’afficher que celles qui répondaient aux critères de la requête : les anaphores, les lettres du xixe s. av. J.-C. (groupe 2), etc. n’ont pas été retenues. Cette visualisation facilite beaucoup le traitement des données.
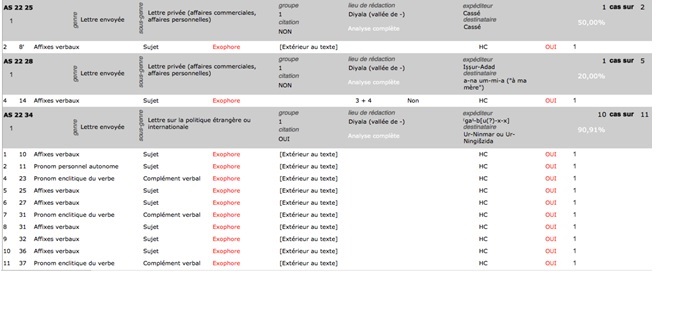
Fig. 5 : Résultat d’une requête croisée dans Lea © Marine Béranger (voir l’image au format original)
{kind=link}
Conclusions
19Cette base de données relationnelle permet d’enregistrer et d’organiser une grande quantité d’informations, et rend possible la mise en relation de données de nature différente ainsi que la visualisation rapide des résultats.
Analyse du vocabulaire et des graphèmes avec le logiciel TXM9
20À l’intérieur des lettres, il est certains motifs, tels le vocabulaire et les graphèmes, qui, présents en grande quantité, sont fastidieux à analyser manuellement. Ils sont pourtant une source d’informations précieuse : le vocabulaire permet d’observer le taux de véhicularité de la langue écrite, et le système graphique, qui évolua beaucoup au cours de l’histoire du cunéiforme, sert à reconstruire les différentes traditions régionales et à estimer le niveau de qualification des scribes. La pénibilité d’une analyse manuelle nous fut épargnée grâce au logiciel TXM (http://textometrie.ens-lyon.fr), développé par l’UMR 5191 ICAR. En rendant possible la prise en charge du corpus des lettres paléo-babyloniennes par l’outil informatique, il a autorisé le traitement automatique du vocabulaire et des graphèmes d’un grand nombre de textes.
Le choix du logiciel TXM
21Logiciel gratuit et open source, TXM supporte de nombreux formats d’import, dont le XML et le XML-TEI. Sans cette souplesse, nous n’aurions pu appliquer à notre corpus les calculs développés pour l’analyse de données textuelles. Afin de quantifier et de comparer le vocabulaire des textes, il est en effet préférable que chaque forme fléchie soit ramenée à une forme canonique (lemme), et que soient précisées certaines informations morphosyntaxiques telles que la catégorie grammaticale10. La plupart des logiciels d’analyse de données textuelles intègre un logiciel d’étiquetage morphosyntaxique. TXM fonctionne par exemple avec TreeTagger, Hyperbase avec Cordial Analyseur et TreeTagger. De nombreuses langues sont aujourd’hui prises en charge par ces lemmatiseurs/étiqueteurs, telles que le latin, le grec et l’ancien français11. Malheureusement, aucun étiquetage automatique n’a été développé pour l’akkadien12. TXM gère cependant les fichiers au format XML et XML-TEI, aussi avons-nous pu contourner cet obstacle majeur en recourant à un étiquetage manuel rédigé selon les normes de la TEI. Grâce à ce procédé, l’ensemble des fonctionnalités implémentées dans TXM est disponible pour notre corpus.
22Logiciel de textométrie, TXM a de plus l’avantage de ne pas se limiter aux mots mais de vouloir étendre les calculs statistiques à un ensemble de paliers de description linguistique (le signe, la phrase, le texte)13. En annotant manuellement ces divers paliers selon les normes de la TEI, et en utilisant l’import XML/w+CSV dans TXM, nous avons pu étudier le vocabulaire, les formes graphiques et les graphèmes des lettres paléo-babyloniennes.
23Enfin TXM permet de comparer les textes à partir d’un ensemble de métadonnées, ce qui, dans le cas de nos recherches, rend par exemple possible la comparaison de lettres rédigées à des dates et dans des villes différentes.
Principes de l’annotation
24La Text Encoding Initiative (TEI) est un consortium qui développe un ensemble de recommandations pour la représentation numérique des textes. Les normes de la TEI sont bien documentées sur internet (http://www.tei-c.org/index.xml). L’encodage que nous utilisons pour les lettres paléo-babyloniennes ne correspond cependant pas toujours aux normes décrites par ce consortium. Il s’agit parfois d’une version adaptée aux particularités du système cunéiforme et à nos besoins spécifiques. Ce qui importe, c’est que l’encodage choisi a très rapidement permis l’import des lettres akkadiennes dans TXM en donnant accès à toutes les fonctionnalités du logiciel.
25Dans cet article, nous nous limiterons à présenter l’encodage du vocabulaire et des signes cunéiformes. La façon dont nous encodons la totalité d’une lettre est présentée sur le site internet dédié à notre projet14.
Encoder le vocabulaire des lettres
26Chaque mot est encodé avec l’élément <w>. La forme fléchie apparaît, sous une forme translittérée en alphabet latin, en tant que valeur de <w>. L’attribut @line précise la ligne à laquelle cette forme apparaît sur la surface de la tablette d’argile. La forme fléchie est réduite à une forme normalisée (lemme) avec l’attribut @lemma. Nous précisons la catégorie grammaticale du lemme avec l’attribut @pos. Pour les verbes, la conjugaison (@tns) et la personne grammaticale (@per) sont précisées.
27Exemple : <w line="12" lemma="damâqum" pos="VV" tns="I perm." per="3MS">da-mi-iq</w>
Encoder les signes cunéiformes
28Chaque signe cunéiforme est encodé avec l’élément <g>. Son indice dans le syllabaire de Rykle Borger et son numéro Unicode sont associés à l’aide des attributs @refSyllab et @refUnicode créés dans le cadre du projet15. La référence Unicode permet d’afficher les caractères cunéiformes dans le logiciel TXM.
29Exemple : <g refSyllab="#MesZL737" refUnicode="#U+121A0">qí</g>
Création des fichiers encodés
30L’informatisation des lettres paléo-babyloniennes impose un encodage complexe. La base de données relationnelle Archibab (http://www.archibab.fr), conçue par le Professeur Dominique Charpin, facilite cette opération. Créée pour mettre en ligne la bibliographie, la translittération et la traduction des documents d’archive paléo-babyloniens, Archibab permet de rechercher des documents à partir d’une forme fléchie ou d’un lemme. Cette dernière requête est possible car les membres de l’équipe Archibab associent aux mots des textes qu’ils entrent dans la base un lemme et une catégorie grammaticale.
31Dominique Charpin a de plus conçu un export des textes au format XML. Cette première version exportée depuis Archibab réunit certaines informations contextuelles sur la lettre (telles que le lieu et la date de rédaction) et associe à chaque forme fléchie son lemme, sa catégorie grammaticale et sa ligne sur la tablette. Il faut ensuite ajouter manuellement l’entête du document, compléter la catégorie grammaticale de certains lemmes pour lesquels Archibab ne propose aucune étiquette grammaticale et préciser la conjugaison et la personne grammaticale des verbes. Pour finir, il reste à annoter la structure de la lettre et à indiquer quels mots ou signes sont partiellement ou totalement restitués.
32Les graphèmes appartiennent à un palier de description linguistique inférieur au mot. Pour cette raison, l’information associée aux signes cunéiformes est enregistrée dans un fichier XML distinct. L’association d’un indice et d’un numéro Unicode à chaque signe est effectuée automatiquement, à l’aide d’une feuille XSLT16.
33Les schémas conçus dans le cadre du projet (Relax NG et XML schéma) permettent de contrôler la conformité de chaque fichier XML créé par rapport à l’encodage XML-TEI choisi pour le projet.
Exemple d’analyse : de la difficulté de rédiger une lettre
34Certains chercheurs pensent qu’en Mésopotamie seuls les scribes professionnels maîtrisaient la complexité du système cunéiforme et étaient capables d’écrire. Dominique Charpin a cependant rappelé qu’il n’y a pas de lien entre la difficulté objective d’un système d’écriture et son utilisation par la population17. De plus, si nos syllabaires rassemblent aujourd’hui un peu plus de 600 signes cunéiformes, beaucoup sont spécifiques à une région, à une époque ou à un genre18. Les signes utilisés dans les recueils de présage ne sont, par exemple, pas les mêmes que ceux des documents administratifs.
35Une façon d’appréhender la complexité du système cunéiforme, donc la possibilité pour les rédacteurs d’écrire eux-mêmes leurs lettres, consiste à évaluer le nombre de signes requis en moyenne pour rédiger un message19. Pour ce faire, nous avons utilisé deux lots de lettres administratives écrites au xviiie s. av. J.-C., trouvées intactes par les archéologues. Les unes proviennent de la ville de Mari (55 lettres), les autres de Babylone (62 lettres)20.
Les étapes de l’analyse
36Notre corpus de lettres est composé de textes rédigés dans une dizaine de villes mésopotamiennes et produits dans des contextes différents. Dans TXM, nous avons pu sélectionner uniquement les lettres administratives de Babylone et de Mari en créant un sous-corpus. Nous avons ensuite demandé au logiciel d’établir la liste des signes cunéiformes non suppléés par l’éditeur21 utilisés dans chacune des lettres administratives. Les lettres ont pu être étudiées séparément en créant une « partition ». Le logiciel a affiché les résultats de notre requête dans un tableau (fig. 6).
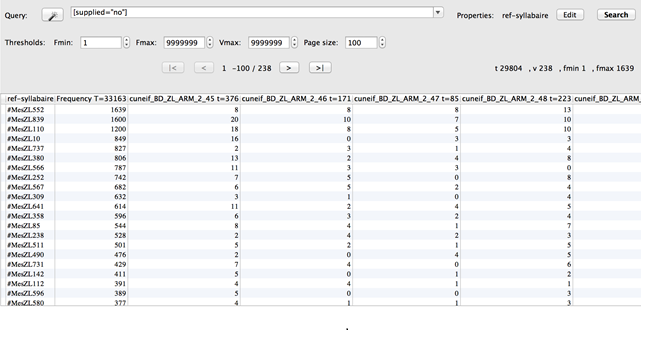
Fig. 6 : Table lexicale des signes utilisés dans chacune des lettres administratives de Mari et de Babylone © Marine Béranger (voir l’image au format original)
{kind=link}
37Les colonnes du tableau correspondent aux différentes lettres administratives du corpus et les lignes aux différents signes cunéiformes. À l’intersection d’une ligne et d’une colonne se trouve la fréquence du signe dans la lettre. Chaque signe est identifié à l’aide du numéro qui lui a été attribué dans le syllabaire de Rykle Borger.
38Afin de calculer le nombre de signes cunéiformes en moyenne requis pour rédiger une lettre administrative, nous avons exporté vers un tableur les résultats obtenus dans TXM (fig. 7).

Fig. 7 : Post-traitement des données dans un tableur (Calc) © Marine Béranger (voir l’image au format original)
{kind=link}
39L’emploi des logogrammes, qui représentent un mot entier (contrairement aux phonogrammes qui représentent une partie de la forme sonore d’un mot), s’ils sont en nombre limité, permet de diminuer le nombre de signes graphiques à utiliser et, par extension, à mémoriser22. Désirant évaluer la difficulté que représentait l’écriture d’une lettre administrative au iie mil. av. J.-C., nous avons voulu connaître le nombre d’idéogrammes et de phonogrammes utilisés dans notre corpus. Ces deux types de réalisation graphique ont pu être traités séparément dans TXM grâce à des requêtes CQL (Corpus Query Language)23.
40Finalement, avec les données reccueillies au cours de la présente étude, nous avons commencé à constituer la liste des signes graphiques utilisés dans la production épistolaire. Dans la suite de nos recherches, cette liste permettra de comparer les signes utilisés par les scribes de Mari et ceux de Babylone (fig. 8).
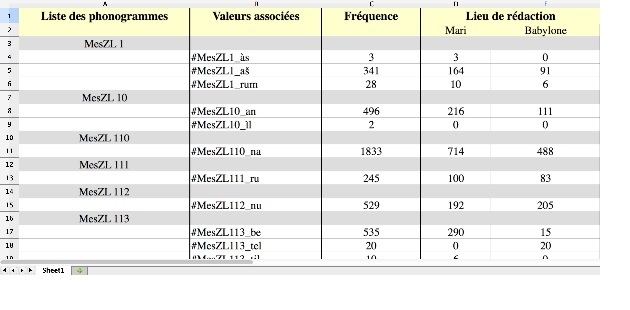
Fig. 8 : Le syllabaire de Mari et de Babylone © Marine Béranger (voir l’image au format original)
{kind=link}
Conclusions
41Au total, 166 signes différents ont été recensés dans les 55 lettres administratives de Mari. Nous sommes loin des 600 signes recensés dans les syllabaires actuels ! En moyenne, les scribes ont eu besoin de 61 signes pour les écrire. Elles furent presque entièrement rédigées avec les mêmes signes (58 signes apparaissent au moins une fois dans la moitié des lettres du corpus). Le syllabaire minimum, trouvé dans la lettre ARM 6 48, comprend 32 signes.
42Nous avons recensé 195 signes dans les 62 lettres administratives de Babylone. En moyenne, les scribes ont eu besoin de 54 signes pour écrire ces lettres. Comme à Mari, elles furent presque entièrement rédigées avec les mêmes signes (41 signes apparaissent au moins une fois dans la moitié des lettres). Le syllabaire minimum, trouvé dans la lettre AbB 13 42, est composé de 29 signes.
43Si 116 phonogrammes furent utilisés à Mari et 120 à Babylone, les scribes ont en moyenne utilisé 56 phonogrammes à Mari et 44 à Babylone. C’est beaucoup moins que les estimations proposées par D.-O. Edzard pour cette période (ca. 80 signes)24.
44Les lettres que nous avons étudiées furent probablement rédigées par des scribes palatiaux. Ces résultats révèlent que les scribes professionnels utilisaient eux-mêmes un nombre de signes restreint lorsqu’ils rédigeaient une lettre. Le peu de signes requis permet de remettre en cause l’idée de la complexité du système cunéiforme.
45L’hypothèse que les lettres pouvaient être rédigées par des individus qui n’étaient pas des professionnels de l’écrit est confortée par les données archéologiques25, textuelles et prosopographiques26 : nous savons en effet que plusieurs individus, la plupart au service de l’administration royale, avaient reçu une formation scribale minimale.
Conclusion générale
46On assimile souvent les humanités numériques à des technologies capables de traiter plus facilement, plus rapidement et en plus grande quantité les données. Or, les outils numériques requièrent un apprentissage de la part du chercheur et le travail préparatoire (tel que la conception d’une base de données relationnelle ou l’encodage des sources) peut être chronophage. Nos derniers mots insisteront sur le fait que le chercheur devra se montrer patient avant d’obtenir les premiers résultats.
Documents annexes
- Fig. 1 : Lettre AS 22 6
- Fig. 2 : Informations générales
- Fig. 3 : Les chaînes de référence dans AbB 2 28, lettre du XVIIIe s. av. J.-C
- Fig. 4 : Exemple de requête croisée dans Lea
- Fig. 5 : Résultat d'une requête croisée dans Lea
- Fig. 6 : Table lexicale des signes utilisés dans chacune des lettres administratives de Mari et de Babylone
- Fig. 7 : Post-traitement des données dans un tableur (Calc)
- Fig. 8 : Le syllabaire de Mari et de Babylone